NOTE: The plan was to publish all the blogs when I finished the deployment. Unfortunately, the deployment is paused due to heavy workload but I am publishing the first few parts already
Planning
My home lab consists of two ESXi 8.0 servers, a QNAP for Network storage, switches and firewalls. A LOT of firewalls 🙂
As the number of VMs running on ESXi keeps growing, I was thinking of implementing a Kubernetes* Cluster to move some of the services in this cluster, reduce the number of running VMs and provide High Availability.
HA for a home lab? Well yes, why not. 🙂
Anyway, I read some of the documentation and due to my home lab limitations, lack of time, sleep etc, I opted to go with K3s and Rancher along with Longhorn, which seems to be a solution that fits my needs and will not take forever to build.
Now, I would need two clusters. One for the internally hosted services accessible only from my internal network and one for the DMZ where some services can be accessible from the internet.
As Rancher can easily deploy a Kubernetes cluster with a few clicks on vSphere first I need to deploy Rancher 2.7 aaaand Longohorn 1.4.0 aaaand it has to be of course Highly Available. This cluster will also host the internal services.
To get started with an HA K3s cluster you need:
- Two physical machines running preferably the same hypervisor if of course you are using VMs.
- A load balancer to manage the cluster using one IP.
- A database.
- Some server (Master) nodes.
- Some worker (Agent) nodes.
- A VM? that will be used to manage the cluster(s) via cli
Decisions
- I am already using vSphere and I have esxi0 and esxi1
- As a load balancer I am going to use HAproxy on pfsense. As my pfsense deployment is already HA, I am good. pfsense will be used also as a reverse proxy, SSL termination and for requesting certificates from Let’s Encrypt
- Database. An external MySQL or Postgres DB would mean to have two more VMs so I opted to go for the embedded database – ETCD, that automatically replicates between server nodes and there is no need for additional VMs (yay!). But in order to have Fault Tolerance you need to have at least 3 copies and if one fails then the cluster still functions. So…..
- 3 Master nodes. (Someone said something about reducing the amount of VMs…) Cannot do without them…
- *Optional 3 Worker nodes. In my case these nodes are physical as I had three Raspberry PI 4s with 8Gb of RAM and 1Tb of USB SSD disk. These will be used mostly for storage. More on that later.
- One more Ubuntu VM to manage the cluster(s). This can be a Windows PC with or without WSL but I opted….well for one more VM…
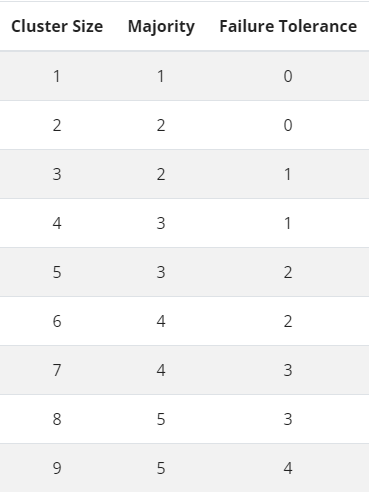
etcd database fault tolerance table
* Kubenetes from the Greek word Κυβερνήτης pronounced Kivernitis and means governor, commander, captain (of a ship) etc